全局解释器锁(Global Interpreter Lock,简称 GIL)是 Python 编程语言(特指 CPython 参考实现)中最具争议、最被误解,同时也最核心的技术特征之一。
自 Python 诞生以来的三十余年间,GIL 作为 CPython 内存管理和线程安全模型的基础,既成就了 Python 在单线程脚本和胶水语言领域的霸主地位,也成为了其在多核并发计算时代面临的最大技术债务 。
锁的设计哲学
在 CPython 中,每个 Python 对象都有一个 ob_refcnt 字段记录引用次数。一旦归零,内存立即回收。这种机制简单高效,但在多线程下并不安全。
在多线程环境下,如果两个线程同时对同一个对象执行 del 操作(即 ob_refcnt--),且没有锁保护,就可能发生竞态条件(Race Condition),导致计数器计算错误,进而引发内存泄漏或程序崩溃。
为了解决上述问题,CPython 选择了粗粒度锁(GIL):强制规定在任何一个 Python 进程内,无论有多少个 CPU 核心,同一时刻只能有一个线程处于“解释执行 Python 字节码”的状态。
GIL 的具体实例
GIL 的存在导致 Python 多线程在处理不同类型任务时表现出截然不同的性能特征。
CPU 密集型任务的并行度为零
在 CPython(默认有 GIL)下,纯 Python 字节码层面的 CPU 密集计算,多线程无法并行,反而因为锁竞争(GIL Context Switching)导致比单线程更慢。
如果计算主要发生在会释放 GIL 的 C/Fortran 扩展(如部分 NumPy/BLAS/OpenCV 调用)中,则线程可能在扩展内部实现真正的多核并行;本节讨论的是“Python 字节码主导”的 CPU 密集循环。
代码:
import time
import threading
def cpu_bound_task(n):
"""纯 CPU 计算任务:递减计数"""
while n > 0:
n -= 1
COUNT = 100_000_000
# 1. 单线程
start = time.time()
cpu_bound_task(COUNT)
print(f"单线程: {time.time() - start:.4f} seconds")
# 2. 多线程 (2个线程,各跑一半任务)
t1 = threading.Thread(target=cpu_bound_task, args=(COUNT // 2,))
t2 = threading.Thread(target=cpu_bound_task, args=(COUNT // 2,))
start = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
print(f"多线程: {time.time() - start:.4f} seconds")输出:
单线程: 3.2728 seconds
多线程: 3.3046 seconds
多线程版本通常比单线程版本慢或者持平。这是因为两个线程在单个 CPU 核心上争抢 GIL,产生了额外的上下文切换开销,却无法并行执行。
I/O 密集型任务的伪并行
当 Python 线程执行 I/O 操作(如读写文件、网络请求、time.sleep)时,它会主动释放 GIL。这使得 Python 多线程在 I/O 密集型场景下非常有效。
代码:
import time
import threading
def io_bound_task(sec):
"""模拟 I/O 等待"""
time.sleep(sec)
# 1. 单线程执行 (预期 2 秒)
start = time.time()
io_bound_task(1)
io_bound_task(1)
print(f"单线程 I/O: {time.time() - start:.4f} seconds")
# 2. 多线程执行 (预期 1 秒)
t1 = threading.Thread(target=io_bound_task, args=(1,))
t2 = threading.Thread(target=io_bound_task, args=(1,))
start = time.time()
t1.start(); t2.start()
t1.join(); t2.join()
print(f"多线程 I/O: {time.time() - start:.4f} seconds")输出:
单线程 I/O: 2.0017 seconds
多线程 I/O: 1.0015 seconds
多线程版本耗时几乎减半。这是因为线程 A 在 sleep 时释放了 GIL,线程 B 立即获得 GIL 并运行,实现了并发等待。
护送效应(Convoy Effect)
当 CPU 密集型线程(如后台压缩数据)与 I/O 密集型线程(如 UI 响应)共存时,CPU 线程会频繁霸占 GIL,导致 I/O 线程唤醒后难以抢到锁,造成 UI 卡顿或网络延迟抖动。
传统规避方案
在 PEP 703 之前,为了利用多核,最通用的方案是 multiprocessing。
多进程:以空间换时间
代码:
import time
from multiprocessing import Pool
def cpu_bound_task(n):
while n > 0:
n -= 1
if __name__ == "__main__":
COUNT = 100_000_000
tasks = [COUNT // 2, COUNT // 2]
with Pool(processes=2) as p:
start = time.time()
p.map(cpu_bound_task, tasks)
end = time.time()
print(f"多进程: {end - start:.4f} seconds")输出:
多进程: 1.7697 seconds
相比多线程,多进程能利用多核 CPU,速度显著提升(通常快 1.8-2 倍)。但代价是内存占用翻倍以及进程间通信(IPC)的高开销 。
注意:
- 保留了
if __name__ == '__main__':,这在 Windows 系统上是运行多进程必须的,否则会陷入无限递归创建子进程的死循环 - 原因:
- Windows 的生成(Spawn)机制: 在 Windows 上,Python 无法像 Linux 那样直接克隆父进程。它必须启动一个全新的 Python 解释器,然后把你的
.py文件重新导入(Import)一遍,以便让子进程知道有哪些函数可以运行。 - 递归爆炸:
- 主进程运行代码,遇到
Pool(2)。 - 主进程启动子进程 A。
- 子进程 A 为了运行,会重新导入你的
.py文件。 - 如果没有保护,子进程 A 在导入时也会执行到
Pool(2)这行代码。 - 于是子进程 A 又去启动子进程 B……
- 循环往复,直到你的系统资源(内存/进程数)耗尽,电脑直接卡死或崩溃。
- 主进程运行代码,遇到
- Windows 的生成(Spawn)机制: 在 Windows 上,Python 无法像 Linux 那样直接克隆父进程。它必须启动一个全新的 Python 解释器,然后把你的
多进程带来的问题
1. 极其昂贵的通信开销 (IPC & Serialization)
这是多进程最大的痛点。
- 问题核心: 进程间内存是不共享的。为了在进程间传递数据(比如主进程把任务分发给子进程,或子进程返回结果),Python 必须对数据进行 序列化 (Pickling) 和 反序列化。
- 后果:
- 如果处理大数据(比如传递一个几 GB 的 NumPy 数组或大的图像数据),CPU 会花费大量时间在“打包”和“拆包”数据上,而不是在做实际计算。
- 有时通信的耗时甚至超过了并行计算节省下来的时间,导致“多核反而变慢”。
2. 内存占用膨胀 (Memory Overhead)
- 问题核心: 每个子进程都是一个完整的 Python解释器实例。
- 后果:
- 这意味着如果主程序占用了 1GB 内存,开启 4 个子进程,理论上可能瞬间占用接近 4-5GB 的内存。
- 虽然 Linux 系统有 Copy-on-Write (写时复制) 机制,在只读数据时能节省内存,但 Python 的引用计数机制(Reference Counting)会导致即便是“读取”变量也会修改内存(更新引用计数),从而频繁触发页面复制,破坏 Copy-on-Write 的优化效果。
3. “全局变量”陷阱与状态隔离
- 问题核心: 很多新手会踩的坑。你在主进程修改了全局变量,子进程是看不到的,因为子进程拥有的是该变量的一个副本。
- 代码示例:
import multiprocessing
data = []
def worker():
data.append(1) # 这里修改的是子进程里的 data
print(f"Worker data: {data}")
if __name__ == '__main__':
p = multiprocessing.Process(target=worker)
p.start()
p.join()
print(f"Main data: {data}") # 主进程的 data 依然是空的!输出:
Worker data: [1]
Main data: []
- 解决成本: 必须使用
multiprocessing.Manager、Queue或Pipe等复杂的同步原语,编写代码的复杂度远高于多线程。
4. 进程创建与销毁的开销 (Context Switching)
- 对比: 启动一个线程(Thread)非常轻量;启动一个进程(Process)则涉及到操作系统分配独立的内存空间、文件描述符等,开销大得多。
- Windows vs Linux:
- 在 Linux 上使用
fork启动较快,但容易有线程安全问题。 - 在 Windows/macOS 上默认使用
spawn,不仅启动慢,还要求所有传递给子进程的对象必须是可被 pickle 的(Picklable),这导致很多复杂的对象(如带锁的对象、lambda 函数)无法直接传递。
- 在 Linux 上使用
5. 难以调试 (Debugging Nightmare)
- 当子进程抛出异常时,错误堆栈有时会被截断或者很难直接关联到主进程的逻辑。
- 标准的调试器(如 pdb)在多进程环境下很难直接断点调试子进程,通常需要专门的工具或技巧(如 remote debugger)。
| 特性 | 标准多线程 (GIL) | 多进程 (Multiprocessing) | No-GIL 多线程 (Python) |
|---|---|---|---|
| CPU 利用率 | 单核 (100% total) | 多核 (True Parallel) | 多核 (True Parallel) |
| 内存开销 | 低 (共享内存) | 极高 (独立内存) | 低 (共享内存) |
| 数据通信 | 零拷贝 (直接读写) | 慢 (需序列化/IPC) | 零拷贝 (直接读写) |
| 适用场景 | IO 密集型 | CPU 密集型 | 全能 (IO & CPU) |
| 代码复杂度 | 中 (需注意锁) | 高 (需处理 IPC/Pickle) | 中 (更需要注意锁!!) |
| 调试难度 | 低 | 高 | 很高(竞态) |
结论:
多进程是为了绕过 GIL 而采用的一种“以空间(内存)换时间”的妥协方案。
一旦 Python 的 No-GIL 生态成熟(库适配完成),多进程方案在单机并发场景下将不再是首选,因为它既费内存又因为通信导致延迟高。
革命性突破:PEP 703 与自由线程 Python
下载无 GIL 的 Python
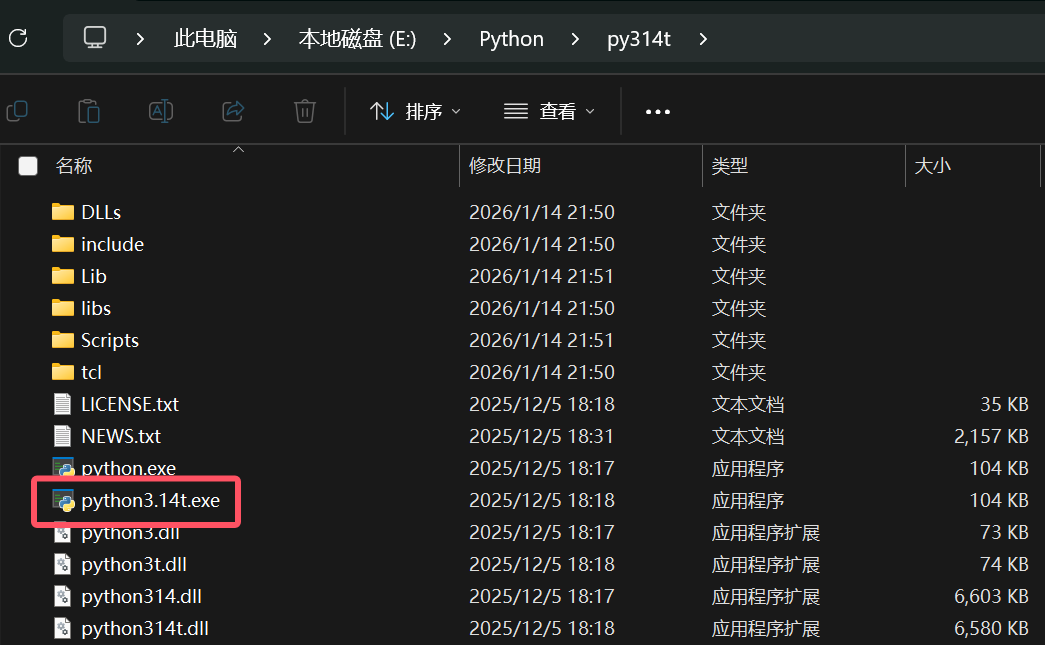
官网下载 installer,选择自定义安装,在 Advanced Options 中,勾选 free-threaded 版本

然后在安装目录下会有两个python解释器,选择带 t 的版本
验证:
& E:/Python/py314t/python3.14t.exe -X gil=0 -c "import sys; print(f'解释器路径: {sys.executable}'); print(f'GIL 是否已禁用: {not sys._is_gil_enabled()}')"- 参数:
-X gil=0 - 可以运行
print(sys._is_gil_enabled())。如果结果是False,说明该执行文件默认就禁用了 GIL,不需要额外输入-X gil=0
输出:
解释器路径: E:\Python\py314t\python3.14t.exe
GIL 是否已禁用: True
为什么官方要分两个文件?这是为了生产环境的安全考虑。
- 标准版 (
python.exe):性能经过数十年优化,最稳定,支持所有第三方库,但受 GIL 限制。 - 自由线程版 (
python3.14t.exe):允许真正的多核并行,但因为内部加锁机制改变,单线程任务可能变慢,且部分旧的 C 扩展库可能会崩溃。
多线程性能检验
代码:
import time
import threading
import sys
def cpu_task():
count = 0
for i in range(10_000_000):
count += i
def run():
print(
f"Python版本: {sys.version.split()[0]} | GIL: {'禁用' if not sys._is_gil_enabled() else '开启'}"
)
# 1. 单线程顺序执行
start = time.time()
cpu_task()
cpu_task()
t_single = time.time() - start
print(f"单线程(顺序执行2次): {t_single:.4f} 秒")
# 2. 多线程并行执行
t1 = threading.Thread(target=cpu_task)
t2 = threading.Thread(target=cpu_task)
start = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
t_multi = time.time() - start
print(f"多线程(并行执行2次): {t_multi:.4f} 秒")
print(f"加速比: {t_single / t_multi:.2f}x")
if __name__ == "__main__":
run()输出:
Python版本: 3.14.2 | GIL: 禁用
单线程(顺序执行2次): 0.5047 秒
多线程(并行执行2次): 0.2557 秒
加速比: 1.97x
No-GIL 更需要注意锁!!
很多人有一个误区:以为“去掉了 GIL”就等于“多线程自动变快且变安全”。 实际上,No-GIL 是把“解释器级别的锁”去掉了,但这把保护用户数据的责任完全扔回给了你(开发者)。
1. 以前 GIL 给你提供了“意外的保护”
在有 GIL 的时代,Python 即使是多线程,同一时刻也只有一个线程在执行字节码。这带来了一种副作用(或者说福利):很多操作在宏观上看起来像是“原子”的,因为在一个极短的时间片内,其他线程根本插不进来。
- 旧时代 (有 GIL): 两个线程同时往一个 list 里
append数据,通常不会导致 Python 崩溃(Segfault),因为 GIL 保证了 C 语言层面的list结构体不会被并发修改破坏。 - 新时代 (No-GIL): 两个线程是真正在物理核上并行跑。如果 Python 内部不给 list 加细粒度锁(Free-threaded Python 确实给内置类型加了内部锁以防止解释器崩溃),数据竞争发生的概率会指数级上升。
2. “线程安全” vs “解释器安全”
No-GIL 的 Python 解释器在内部做了大量工作(比如给引用计数加原子操作、给字典和列表加细粒度锁),但这只能保证解释器不崩溃。它不能保证你的业务逻辑是正确的。
dict/list/set等内置类型用了内部锁,目标是在 Python 层面提供与有 GIL 时“相似”的线程安全体验,但这不等于用户代码逻辑就一定正确。来源:官方 free-threading HOWTO

经典案例:n += 1 不是原子的 无论有没有 GIL,n += 1 都要分三步走:
- 读取
n的值 - 计算
n + 1 - 把结果写回
n
- 有 GIL 时: 线程切换可能发生在步骤 1 和 2 之间,导致计数错误。但由于 GIL 的存在,这种切换频率受限于
sys.setswitchinterval。 - No-GIL 时: 两个线程可能同时(在不同的 CPU 核上)读取了旧的
n,同时计算,然后同时写回。这种“竞态条件” (Race Condition) 的窗口期比有 GIL 时大得多,极易复现。
你需要显式加锁:
import threading
lock = threading.Lock()
n = 0
def worker():
global n
# 在 No-GIL 模式下,这里必须加锁,否则数据必错
with lock:
n += 1 dis 字节码验证:
import dis
def inc():
global n
n += 1
dis.dis(inc)输出:
2 0 RESUME 0
4 2 LOAD_GLOBAL 0 (n)
12 LOAD_CONST 1 (1)
14 BINARY_OP 13 (+=)
18 STORE_GLOBAL 0 (n)
20 RETURN_CONST 0 (None)
这些步骤不是原子操作:在有 GIL 的情况下,线程切换可能发生在字节码之间;在 No-GIL 下,不同线程甚至可能在不同 CPU 核上同时执行这些步骤,从而产生写回覆盖。
可以用一段代码测试一下:
import threading
import time
import sys
# 1. 设置参数
TARGET_PER_THREAD = 1000000 # 每个线程加 100万次
THREAD_COUNT = 8 # 开启 8 个线程(利用你的多核)
# 2. 共享变量
n = 0
def worker():
global n
for _ in range(TARGET_PER_THREAD):
# === 核心冲突点 ===
# n += 1 实际上包含三步:
# 1. LOAD_GLOBAL (读取 n 的当前值)
# 2. BINARY_OP_ADD (计算 n + 1)
# 3. STORE_GLOBAL (把结果写回 n)
# 在 No-GIL 下,多个线程会在物理核上同时做这三步,互相覆盖。
n += 1
def run_test():
global n
n = 0
threads = []
print(f"Python 版本: {sys.version.split()[0]}")
print(f"GIL 状态: {'已开启' if sys._is_gil_enabled() else '已关闭 (No-GIL)'}")
print(f"期望结果: {TARGET_PER_THREAD * THREAD_COUNT}")
print("开始疯狂计算...")
start_time = time.time()
# 创建并启动线程
for _ in range(THREAD_COUNT):
t = threading.Thread(target=worker)
threads.append(t)
t.start()
# 等待所有线程结束
for t in threads:
t.join()
end_time = time.time()
expected = TARGET_PER_THREAD * THREAD_COUNT
diff = expected - n
loss_rate = (diff / expected) * 100
print("-" * 30)
print(f"最终结果: {n}")
print(f"丢失次数: {diff}")
print(f"丢失比例: {loss_rate:.2f}%")
print(f"耗时: {end_time - start_time:.4f} 秒")
print("-" * 30)
if __name__ == "__main__":
# 如果是旧版本 Python,sys._is_gil_enabled 可能不存在,这里做个兼容
if not hasattr(sys, "_is_gil_enabled"):
sys._is_gil_enabled = lambda: True
run_test()python3.14t 的返回:
Python 版本: 3.14.2
GIL 状态: 已关闭 (No-GIL)
期望结果: 8000000
开始疯狂计算...
------------------------------
最终结果: 1445671
丢失次数: 6554329
丢失比例: 81.93%
耗时: 4.0558 秒
------------------------------
python3.12 的返回:
Python 版本: 3.12.3
GIL 状态: 已开启
期望结果: 8000000
开始疯狂计算...
------------------------------
最终结果: 8000000
丢失次数: 0
丢失比例: 0.00%
耗时: 0.4627 秒
------------------------------
这时候需要手动加锁:
lock = threading.Lock() # 创建一把锁
def worker():
global n
for _ in range(TARGET_PER_THREAD):
with lock: # 显式加锁
n += 1但是你会发现效率特别低,因为 8 个线程在疯狂争抢同一把锁,导致你的多核 CPU 退化成串行,甚至因为上下文切换的开销,比单线程还慢:
Python 版本: 3.14.2
GIL 状态: 已关闭 (No-GIL)
期望结果: 8000000
开始疯狂计算...
------------------------------
最终结果: 8000000
丢失次数: 0
丢失比例: 0.00%
耗时: 10.4546 秒
------------------------------
正确的处理方式是让每个线程在自己的“私有内存”里算,算完了再一次性合并到全局。这样整个程序总共只抢 8 次锁,而不是 8000万次。
这种写法也就是经典的 Map-Reduce 思想:先在本地(局部)疯狂计算(Map),最后再合并结果(Reduce)。这能最大程度减少锁竞争和 CPU 缓存失效。
def worker():
global n
# === 局部变量 (核心优化) ===
# local_sum 是函数内的局部变量,存在于线程自己的栈空间中。
# 其他线程完全访问不到它,所以不需要加锁,速度极快。
local_sum = 0
for _ in range(TARGET_PER_THREAD):
local_sum += 1
# === 关键点 ===
# 只有在 1000万次计算全部完成后,才去抢一次锁。
# 整个程序总共只抢 8 次锁,而不是 8000万次。
with lock:
n += local_sum输出:
Python 版本: 3.14.2
GIL 状态: 已关闭 (No-GIL)
期望结果: 8000000
开始疯狂计算...
------------------------------
最终结果: 8000000
丢失次数: 0
丢失比例: 0.00%
耗时: 0.0329 秒
------------------------------
3. 第三方库的线程安全性 (User Safety)
这可能是目前最大的坑。 很多 Python 的 C 扩展库(比如早期的 NumPy、Pandas 或一些数据库驱动)在编写时是假设有 GIL 存在的。它们依赖 GIL 来保护它们的全局状态。
- 现状: 如果你在 No-GIL Python 下运行一个尚未适配 No-GIL 的 C 扩展库,可能会直接导致 Segmentation Fault (段错误/崩溃)。
- 解决: 库维护者需要重写代码,用细粒度的锁代替 GIL。在你使用这些库时,如果它们声明支持 Free-threading,通常意味着它们内部处理好了锁;如果未声明,你需要自己加锁保护对这些库对象的访问。
4. 性能陷阱:锁竞争 (Lock Contention)
这是 No-GIL 最尴尬的地方。 为了保护数据,你可能会在代码里加很多 threading.Lock。
- 如果锁加得太多、粒度太粗,线程之间就会频繁争抢锁。
- 结果: 你的多核 CPU 实际上大部分时间都在等待锁释放,性能可能还不如单线程。
- 策略: 在 No-GIL 时代,你需要更高级的并发模型,比如尽量使用无锁数据结构(虽然 Python 里很少),或者使用
queue.Queue这种线程安全的队列来通信,而不是共享全局变量(虽然安全,但是速度会下降很多)。
补充
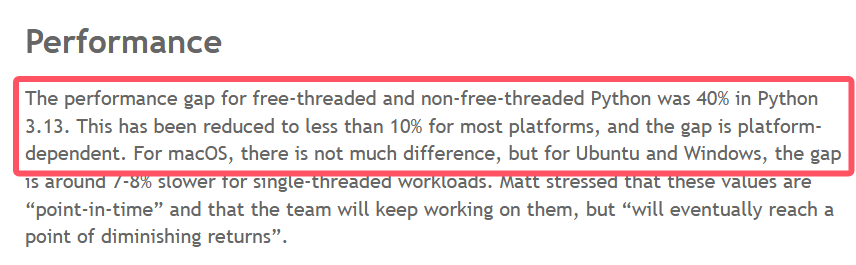
单线程性能回退(Trade-off)
PEP 703 明确提到,Free-threaded Python 在单线程模式下,性能比标准版 Python 要慢。
- 原因:为了支持细粒度锁和引用计数的线程安全,解释器内部增加了很多开销(Overhead)。它牺牲了单线程的极致速度来换取多核的扩展性。
free-threaded 与普通 build 的单线程性能差距是平台相关、点对点的,并且已经被优化到“多数平台 <10%”(比如 Ubuntu/Windows 大约 7–8%,macOS 差异更小;早期 3.13 时差距更大)来源:PSF官方博客