基本概念
指针是存储内存地址的变量,通过 & 获取变量地址,* 解引用指针访问值
int x = 10;
int* ptr = &x; // ptr 存储 x 的地址
cout << *ptr; // 输出 10(解引用)指针与const
1、const int*:指向常量的指针
含义:指针指向的数据是常量,不能通过指针修改,但指针本身可以指向其他地址。
用途:保护数据不被意外修改(如函数参数传递只读数据)
const int* ptr; // ptr 可以指向不同的常量,但不能通过 ptr 修改值
int x = 10;
ptr = &x; // 合法
// *ptr = 20; // 错误!不能修改指向的值2、int* const:常量指针
含义:指针本身是常量,不能改变指向的地址,但可以通过指针修改指向的数据。
用途:确保指针始终指向固定的内存(如硬件寄存器映射)
int x = 10;
int* const ptr = &x; // ptr 必须初始化,且不能再指向其他地址
*ptr = 20; // 合法,可以修改 x 的值
// ptr = &another_x; // 错误!不能修改指针的指向3、const int* const:指向常量的常量指针
含义:指针本身和它指向的数据都是常量,既不能修改指向,也不能修改数据。
用途:严格保护数据和指针(如全局只读配置)
int x = 10;
const int* const ptr = &x; // ptr 和 *ptr 均不可修改
// *ptr = 20; // 错误!不能修改值
// ptr = &another_x; // 错误!不能修改指向**4、**记忆
const 在 * 左侧 → 数据是常量(const int*)
const 在 * 右侧 → 指针是常量(int* const)
指针与数组
数组名本质是指向首元素的指针,支持指针算术
int x[3] = {10,11,12};
int *ptr = x; // 不需要使用&符号
cout << *ptr++ << endl; // 输出 10
cout << *ptr << endl; // 输出 11*ptr++相当于*(ptr++),指针的优先级很低
但下面这样是不行的,会报错error: lvalue required as increment operand,因为数组名是常量指针
int x[3] = {10,11,12};
cout << *x++ << endl;野指针/空指针/垂悬指针
野指针
定义:声明指针但未赋值,指向随机内存地址(可能是垃圾值)
场景 1:未初始化的指针
int* p; // 未初始化,是野指针
*p = 10; // 危险!可能崩溃场景 2:指针越界
int arr[3] = {1, 2, 3};
int* p = &arr[0];
p += 5; // 越界,变成野指针
cout << *p; // 访问非法内存场景 3:函数返回局部变量地址
int* foo() {
int x = 10;
return &x; // 返回局部变量地址
} // x 被销毁,返回的指针悬空
int* p = foo(); // p 是野指针
cout << *p; // 可能输出垃圾值或崩溃空指针
空指针是指不指向任何有效内存地址的指针,在 C++ 中用 nullptr(或旧版 /C++中的NULL或0)表示。它的核心作用是明确表示“指针当前无效”。
int* ptr = nullptr; // 明确初始化,避免指向随机地址悬垂指针
定义:指针指向的内存已被释放,但指针仍保留原地址,访问会导致未定义行为(崩溃或数据错误)
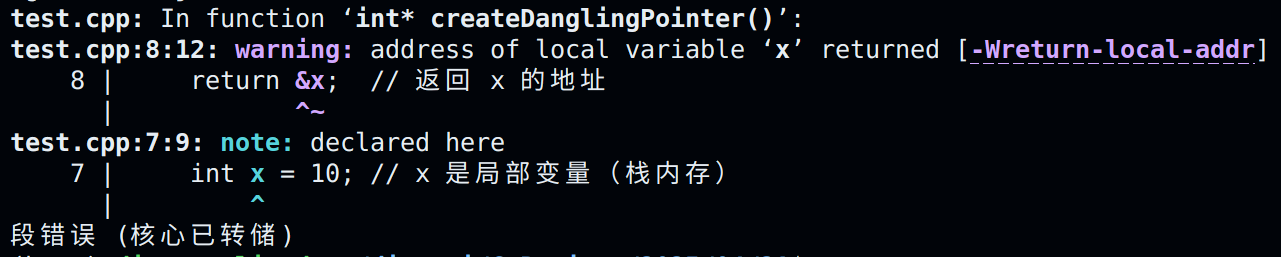
示例1:返回局部变量的指针
int* createDanglingPointer() {
int x = 10; // x 是局部变量(栈内存)
return &x; // 返回 x 的地址
} // 函数结束,x 被销毁,返回的指针悬空!
int main() {
int* ptr = createDanglingPointer();
cout << *ptr; // 危险!访问已释放的内存(可能崩溃或输出垃圾值)
}
示例2:delete 后未置空
int* ptr = new int(10); // 动态分配堆内存
delete ptr; // 释放内存
cout << *ptr; // 危险!ptr 仍是悬垂指针修复方法:释放后立即置空
delete ptr;
ptr = nullptr; // 明确标记为无效指针与传参
在 C++ 中,函数参数传递主要有 3 种方式
传值(Pass by Value)
void func(int x) { x = 10; } // 修改的是副本特点:拷贝实参的值,函数内修改不影响原始数据
优势:简单安全,避免副作用
缺点:拷贝大对象(如结构体、数组)时性能低
传指针(Pass by Pointer)
void func(int* x) { *x = 10; } // 通过指针修改原始数据特点:传递变量的地址,避免拷贝大对象,函数内通过解引用(*x)修改原始数据
优势:1、高效(仅传递地址,4/8 字节);2、显式表达“可能修改数据”的意图
缺点:1、需手动检查空指针(if (x != nullptr));2、可能引发悬垂指针。
void print(int* ptr) {
if (ptr != nullptr) { // 安全检查
cout << *ptr;
} else {
cout << "无数据";
}
}传引用(Pass by Reference)
void func(int& x) { x = 10; } // 直接修改原始数据特点:传递变量的别名,避免拷贝大对象,函数内直接操作原始数据
优势:1、语法简洁(无需 * 和 &);2、无空引用风险(比指针更安全)
缺点:无法表达“可选参数”(引用必须绑定有效对象,即不能传入空指针)
void byRef(int& x) {} // 必须传有效对象
void byPtr(int* x) {} // 可以传 nullptr
int main() {
int a = 10;
byRef(a); // 合法
// byRef(nullptr); // 错误!引用不能为空
byPtr(&a); // 合法
byPtr(nullptr); // 合法:指针可以为空
}指针与内存
动态内存管理
使用 new 和 delete 分配/释放内存,避免内存泄漏
int* p = new int(5); // 动态分配
delete p; // 释放内存内存
在C++中,内存主要分为以下几种类型:
1、栈内存(Stack Memory)
特点:由编译器自动分配和释放内存,分配速度快,大小有限(通常几MB),生命周期与作用域绑定
存储内容:局部变量,函数参数,函数调用信息(返回地址等)
void func() {
int x = 10; // x存储在栈上
} // 函数结束,x自动释放2、堆内存(Heap Memory)
特点:由程序员手动分配(new/malloc)和释放(delete/free),分配速度较慢,可用空间大(受系统内存限制),生命周期由程序员控制
存储内容:动态分配的对象,大块内存需求
int* p = new int(10); // 在堆上分配
delete p; // 必须手动释放3、静态/全局存储区
特点:在程序编译时分配,生命周期贯穿整个程序,分为已初始化区和未初始化区
存储内容:全局变量,静态变量(static),常量
int globalVar; // 未初始化全局变量(.bss段)
static int sVar = 1; // 已初始化静态变量(.data段)
const int cVar = 100; // 常量(可能存储在.rodata段)
+---------------------+
| 栈(stack) | ← 向下生长
+---------------------+
| ↓ |
| ↑ |
+---------------------+
| 堆(heap) | ← 向上生长
+---------------------+
| 未初始化数据(.bss) |
+---------------------+
| 已初始化数据(.data)|
+---------------------+
| 常量存储区(.rodata)|
+---------------------+
| 代码区(.text) |
+---------------------+
| 特性 | 栈内存 | 堆内存 | 静态/全局存储区 |
|---|---|---|---|
| 分配方式 | 自动 | 手动(new/malloc) | 自动 |
| 释放方式 | 自动 | 手动(delete/free) | 程序结束时 |
| 大小限制 | 较小(几MB) | 很大(取决于系统内存) | 较大 |
| 访问速度 | 快 | 较慢 | 中等 |
| 生命周期 | 作用域内 | 直到显式释放 | 整个程序运行期间 |
malloc/free
更准确来说,malloc/free所在的区域是自由存储区,它和new/delete是分开的
malloc/free属于 C 标准库,而new/delete是 C++ 的运算符
| 特性 | malloc/free (C) | new/delete (C++) |
|---|---|---|
| 语言 | C/C++ 通用 | 仅 C++ |
| 初始化 | 不初始化内存 | 调用构造函数(初始化对象) |
| 类型安全 | 需手动类型转换(void*) | 自动类型推导 |
| 失败行为 | 返回 NULL | 抛出 std::bad_alloc 异常 |
| 内存大小 | 需手动计算字节数 | 自动计算类型大小 |
| 适用场景 | 原始内存操作、C 兼容 | 面向对象编程 |
内存泄露
内存泄漏是指程序在 动态分配内存(如 new/malloc)后,未正确释放(delete/free),导致这部分内存无法被系统回收,最终可能耗尽可用内存,引发程序崩溃或性能下降。
内存泄漏的危害:
- 短期影响:程序占用内存逐渐增加,运行变慢
- 长期影响:系统内存耗尽,程序崩溃(尤其在长期运行的服务中)
多级指针与指针数组
二级指针(int**)是指向指针的指针,常用于动态二维数组或修改指针本身。
int x = 10;
int* p = &x; // 一级指针
int** pp = &p; // 二级指针,存储 p 的地址
cout << **pp; // 输出 10(通过二级指针访问 x)
**pp = 20; // 修改 x 的值动态分配二维数组:
int** matrix = new int*[3]; // 分配行指针
for (int i = 0; i < 3; i++) {
matrix[i] = new int[4]; // 分配每行的列
}如何使用这个二维数组:
// 赋值
matrix[0][0] = 1; // 第0行第0列
matrix[1][2] = 5; // 第1行第2列
// 访问
cout << matrix[1][2]; // 输出5为什么不直接声明表格,而用指针来弄?
| 特性 | 直接声明 int matrix[3][4] | 动态分配 int** matrix |
|---|---|---|
| 内存位置 | 栈内存 | 堆内存 |
| 大小确定时间 | 编译时 | 运行时 |
| 是否支持动态大小 | 否 | 是 |
| 内存管理 | 自动(编译器) | 手动(需 delete) |
| 访问速度 | 更快(连续内存) | 稍慢(可能非连续) |
| 适用场景 | 固定大小的小型数组 | 动态大小的中大型数组 |
函数指针与回调
函数指针
函数指针是指向函数的指针变量,允许通过指针调用函数,常用于实现动态行为(如策略模式、回调机制)。
基本语法:返回类型 (*指针名)(参数列表) = 函数名;
#include <iostream>
// 普通函数
int add(int a, int b) { return a + b; }
int subtract(int a, int b) { return a - b; }
int main() {
// 定义函数指针并绑定到 add
int (*funcPtr)(int, int) = add;
// 通过指针调用函数
std::cout << funcPtr(3, 5); // 输出 8
// 切换指向 subtract
funcPtr = subtract;
std::cout << funcPtr(8, 3); // 输出 5
return 0;
}回调(Callback)
回调是一种编程模式,通过将函数指针(或函数对象)传递给其他函数,允许在特定事件发生时被调用。常见于事件驱动、异步编程。
回调的实现方式:
(1)函数指针回调
- processData 函数处理数据
- 处理完成后,通过回调函数 onComplete 通知调用方结果
// 回调函数类型
typedef void (*Callback)(int); // 定义一种函数指针类型,名叫 Callback,参数为int、返回void
// 接受回调的函数
void processData(int value, Callback callback) {
std::cout << "处理数据: " << value << "\n";
callback(value * 2); // 触发回调
}
// 实际回调函数
void onComplete(int result) {
std::cout << "回调结果: " << result << "\n";
}
int main() {
processData(10, onComplete); // 传递回调函数
return 0;
}processData(int value, Callback callback)相当于我是传入了一个函数(具体是什么我不知道,但是方便修改),然后我定义了一个Callback类型来限制我这个传入的函数的样式
Callback相当于一个函数模板,明确约定所有符合这个格式的函数都能传给我,同时限制传入函数的形状
回调vs直接调用:
| 场景 | 直接函数调用 | 回调模式 |
|---|---|---|
| 调用关系 | A → B(A 直接调用 B) | A ⇄ B(A 提供接口,B 决定具体实现) |
| 灵活性 | 固定逻辑,难以扩展 | 可动态替换行为 |
| 适用场景 | 流程固定的简单逻辑 | 需要灵活扩展的框架设计 |
(2)Lambda 表达式回调(C++11+)
#include <functional>
void asyncTask(std::function<void(int)> callback) {
std::cout << "异步任务开始...\n";
callback(42); // 模拟异步完成
}
int main() {
asyncTask([](int result) {
std::cout << "收到回调结果: " << result << "\n";
});
return 0;
}std::function<void(int)>:这是一个通用函数包装器,可以装任何能调用的东西(普通函数、Lambda、类成员函数等)。这里表示:回调函数必须接受一个int参数,且不返回值(void)。
callback(42):任务”完成”后,调用回调函数并传回结果42
[](int x) { std::cout << x; }:[]:捕获列表(这里为空),(int x):参数列表,{ … }:函数体
(3)类成员函数回调
class Processor {
public:
void handleResult(int value) {
std::cout << "处理结果: " << value << "\n";
}
};
template<typename T>
void runTask(T& obj, void (T::*method)(int)) {
(obj.*method)(100); // 调用成员函数
}
int main() {
Processor p;
runTask(p, &Processor::handleResult); // 传递成员函数
return 0;
}模板部分template<typename T>:表示这个函数可以接受任意类型T,具体的T类型是由传入的obj参数自动推导出来的
当调用 runTask(p, &Processor::handleResult) 时:
- 编译器看到第一个参数 p 的类型是
Processor&→ 推导出T = Processor - 第二个参数
&Processor::handleResult的类型是void (Processor::*)(int),与T = Processor一致
&Processor::handleResult 中的 :: 是 作用域解析运算符,用于表示 handleResult 是 Processor 类的成员
void (T::*method)(int)传入&Processor::handleResult之后,*method指向handleResult
现代C++的简化写法:
#include <functional>
template<typename T>
void runTask(T& obj, std::function<void(int)> method) {
method(100); // 直接调用函数对象
}
int main() {
Processor p;
// 用 Lambda 捕获对象并调用成员函数
runTask(p, [&p](int x) { p.handleResult(x); });
}智能指针(C++11+)
智能指针是 C++11 引入的 自动化内存管理工具,用于替代裸指针(int* 等),通过 RAII(资源获取即初始化)机制 自动释放堆内存,从根本上解决内存泄漏和悬垂指针问题。
核心智能指针类型
| 类型 | 头文件 | 所有权语义 | 特点 |
|---|---|---|---|
std::unique_ptr | <memory> | 独占所有权(不可复制) | 轻量高效,移动语义,适合替代 new/delete |
std::shared_ptr | <memory> | 共享所有权(引用计数) | 多个指针可共享同一对象,计数为 0 时自动释放 |
std::weak_ptr | <memory> | 弱引用(不增加引用计数) | 解决 shared_ptr 循环引用问题,需通过 lock() 获取临时 shared_ptr |
std::unique_ptr(独占所有权)
std::unique_ptr 是 C++11 引入的智能指针,核心特性是独占所指向对象的所有权,即同一时间只有一个 unique_ptr 可以拥有该对象。这种设计既保证了内存安全,又几乎无性能开销(与裸指针相当)
独占所有权的含义:
- 唯一性:一个对象只能被一个 unique_ptr 拥有,无法被复制。
- 移动语义:所有权可以通过 std::move 转移给其他 unique_ptr。
- 自动释放:当 unique_ptr 离开作用域时,自动销毁并释放其管理的对象。
(1)基本用法
#include <memory>
// 创建 unique_ptr(推荐 make_unique,C++14 起支持)
auto ptr = std::make_unique<int>(10); // 分配一个 int,初始值为 10
// 访问对象
std::cout << *ptr; // 输出 10
// 自动释放:ptr 离开作用域时,内存自动销毁(2)所有权转移
auto ptr1 = std::make_unique<std::string>("Hello");
auto ptr2 = std::move(ptr1); // 所有权转移给 ptr2
// 此时 ptr1 为 nullptr
if (!ptr1) {
std::cout << "ptr1 已失去所有权";
}
std::cout << *ptr2; // 输出 "Hello"(3)自定义删除器
std::unique_ptr 的自定义删除器(Custom Deleter)用于指定如何释放资源,而不仅仅是默认的 delete 操作。它允许你管理非内存资源(如文件、锁、网络连接等),或者实现特殊的内存释放逻辑(如内存池)。
// 自定义删除器(例如释放文件句柄)
auto FileDeleter = [](FILE* file) {
std::cout << "关闭文件";
if (file) fclose(file);
};
// 管理文件资源
std::unique_ptr<FILE, decltype(FileDeleter)> filePtr(fopen("data.txt", "r"), FileDeleter);默认情况下,unique_ptr用delete释放内存,但以下场景需要自定义行为:
- 管理非内存资源(如文件句柄、数据库连接)。
- 特殊的内存释放需求(如内存池、调试日志)。
- 兼容 C 接口(如 malloc/free)。
自定义删除器让 unique_ptr 不仅限于管理内存,还能安全管理任何需要释放的资源,让 unique_ptr 从内存管理工具升级为通用资源管理工具